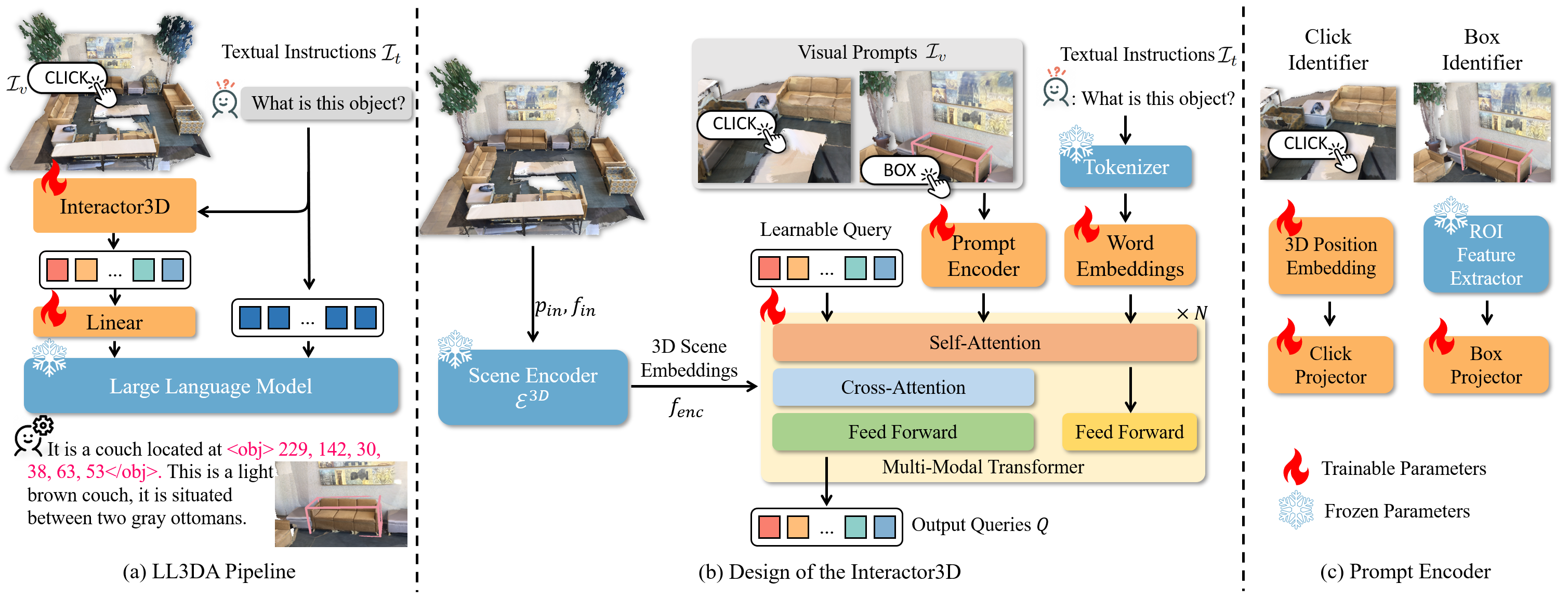
Method
Overview of the Proposed Approach. (a) The overall pipeline of our proposed LL3DA first extracts interaction-aware 3D scene embeddings, which are later projected to the prefix of textual instructions as the input of a frozen LLM. (b) The detailed design of the Interactor3D, which aggregates visual prompts, textual instructions, and 3D scene embeddings into a fixed length querying tokens. (c) The prompt encoder encodes the user clicks and box coordinates with the positional embeddings and ROI features, respectively.